RAG stands for Retrieval-Augmented Generation. It’s a technique used in AI and machine learning—especially in the context of Large Language Models (LLMs)—to enhance their ability to generate factual, context-aware responses by combining retrieval from a knowledge base with natural language generation.
🔧 How RAG Works (Step-by-Step):
- User Query
You ask a question or give a prompt (e.g., “What is the mission of Veritopa?”). - Retrieval Step
Instead of relying solely on its pre-trained knowledge, the system searches a specific external database or document set (like PDFs, websites, or internal company docs) to find the most relevant passages. - Augmentation Step
The retrieved documents or snippets are then fed into the language model as additional context alongside the original question. - Generation Step
The model uses both the prompt and the retrieved content to generate a more accurate, relevant, and current response.
🧠 Why Use RAG?
LLMs like ChatGPT are limited by:
- Training data cutoff dates
- Hallucinations (confidently making stuff up)
- Lack of personalized or private knowledge
RAG overcomes this by:
- Bringing in real-time or domain-specific data
- Providing traceable answers (you can often cite the source)
- Reducing hallucination risk
🧪 Example:
Without RAG:
Q: “What are the latest AI features in Microsoft 365?”
A: The model guesses based on what it knew as of 2023.
With RAG:
The model retrieves real-time documentation or product pages and answers: A: “As of April 2025, Microsoft 365 Copilot includes features like automated meeting summaries, code generation in Excel, and semantic document search, according to Microsoft’s latest changelog.”
🧭 Common Use Cases:
- Enterprise knowledge assistants (e.g., ChatGPT with company docs)
- Legal/medical research tools
- AI-powered customer support
- Academic tutoring and citation-based writing
🔍 Key Assumptions in RAG (to challenge):
- Assumes retrieval corpus is up-to-date and relevant
→ Counterpoint: If the corpus is stale, RAG won’t help. - Assumes retrieval is accurate
→ Retrieval models (e.g., vector search) can miss relevant documents if not tuned properly. - Assumes LLM integrates the context properly
→ LLMs may still hallucinate or ignore critical parts of retrieved text.
🔁 Alternatives / Adjacent Methods:
- Fine-tuning (update the model’s weights with new data—costly and static)
- Prompt Engineering (less reliable for dynamic data)
- Toolformer-style agentic chaining (models call tools like APIs, browsers, etc.)
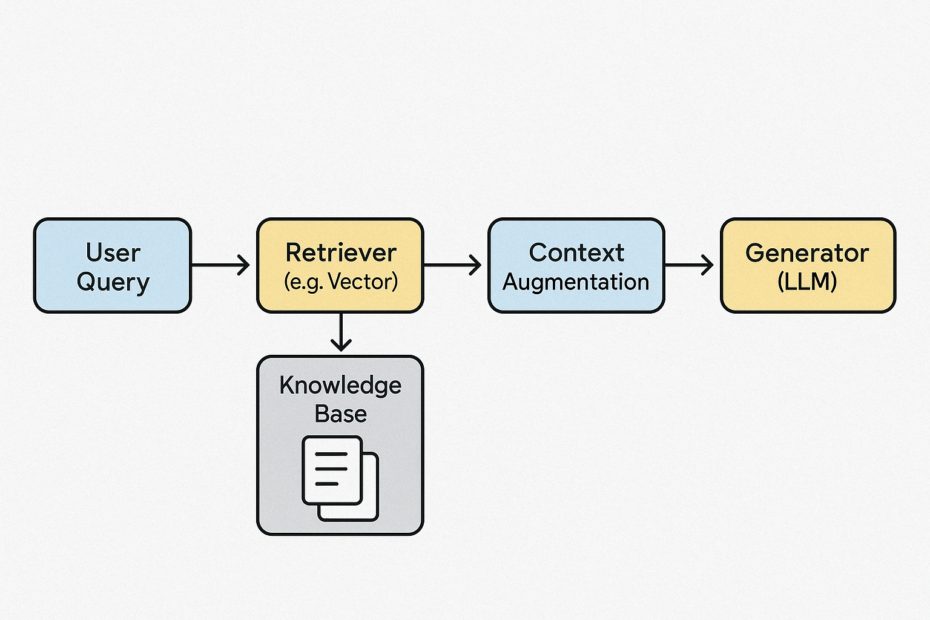
Let’s break down the RAG architecture so you can see how the pieces fit together and how to think critically about each stage. Here’s the canonical architecture of a Retrieval-Augmented Generation system, often built using frameworks like LangChain, LlamaIndex, or Haystack:
🧱 RAG Architecture: High-Level Overview
┌────────────┐ ┌──────────────┐ ┌──────────────┐ ┌─────────────┐
│ User │ ───▶ │ Retriever │ ───▶ │ Context │ ───▶ │ Generator │
│ Query │ │ (e.g. Vector)│ │ Augmentation │ │ (LLM) │
└────────────┘ └──────────────┘ └──────────────┘ └─────────────┘
🔍 1. Retriever Layer
Goal: Find the most relevant documents or chunks in a corpus.
Components:
- Vector Store (e.g., FAISS, Pinecone, Weaviate)
- Embedding Model (e.g., OpenAI Ada, Cohere, HuggingFace models)
- Indexing Strategy
- Chunk size and overlap
- Metadata filtering (e.g., doc type, author, date)
Common Pitfall:
- Bad chunking or irrelevant metadata can weaken retrieval quality.
Counterpoint: Always test retrieval relevance independently of generation.
🧩 2. Context Augmentation (Fusion Layer)
Goal: Inject retrieved content into the prompt in a way the LLM can use effectively.
Strategies:
- Naive Concatenation: Just drop top-k results into the prompt
- Structured Prompting: Use templates like:
You are an assistant answering based on the following context:
chunk1
chunk2 Question: …
Context Ranking: Dynamically re-rank retrieved chunks for coherence and quality
Risks:
- Context overload → Token limits hit or model ignores important chunks
Counterpoint: Use semantic filters and summarize chunks when needed.
🤖 3. Generator (LLM)
Goal: Generate a human-readable, context-aware response
Commonly Used Models:
- OpenAI GPT-4, Claude, Mistral, LLaMA, etc.
- Local models (for privacy-sensitive environments)
Features to Consider:
- Citations / source attribution
- Chain-of-thought reasoning
- Function/tool calling (for advanced agents)
Tradeoff:
- LLMs may still hallucinate or ignore context
Alternative Perspective: Some RAG systems use multi-turn reasoning or verification steps to improve factual accuracy.
🗃️ Optional Layers:
🔁 Feedback Loop (Active Learning)
- Logs user feedback to improve the retriever or refine chunking
📜 Memory Layer (Agentic Systems)
- Stores past interactions or facts about the user
🛡️ Guardrails Layer
- Fact-checking, citation matching, red-teaming filters
🔧 Tooling to Implement It
- LangChain: Modular pipelines for retrieval + LLMs
- LlamaIndex: Index-centric approach; excels at context compression
- Haystack: Good for enterprise RAG with Elastic or OpenSearch backends
- Vector DBs: Pinecone, Weaviate, Chroma, Qdrant
- Embeddings: OpenAI, Cohere, SentenceTransformers
👊 Bonus: Real-World Architecture Patterns
| Use Case | Retrieval Source | Gen Model | Notes |
|---|---|---|---|
| Legal Assistant | Contracts in private S3 | GPT-4 / Claude | Needs tight metadata |
| Internal Knowledgebase Chat | Confluence, Notion, PDF | GPT-4-turbo | Fast retrieval + summarization |
| Academic Research Assistant | ArXiv, PubMed | Mistral + search | May include browser tools |
| Customer Support Bot | Zendesk, docs, tickets | GPT-3.5 | Works with hybrid search |